- Published on
译文:Zed解码:文本坐标系统
原文:https://zed.dev/blog/zed-decoded-text-coordinate-systems 作者:Thorsten Ball, Nathan Sobo, Antonio Scandurra
译者:Claude 3.5 Sonnet
发布时间:06/27/24
Zed解码:文本坐标系统
当有人问你"你的光标在哪里"时,你会怎么说?可能是"第18行",或者如果你心情不错,而且是个个位数,你可能会加上列数:"第18行,第5列"。行和列 — 简单,容易。
文本编辑器,包括Zed在内,也使用行和列来描述位置,但是 — 当我第一次探索Zed的代码库时,让我惊讶的是 — Zed中还有很多其他的坐标系统。有偏移量,UTF-16中的偏移量,显示点和锚点。
为了最终理解这些不同的文本坐标系统以及何时使用哪一个,我与Zed的两位联合创始人Nathan和Antonio交谈,请他们带我从Point到DisplayPoint再到Anchor一一走过。
配套视频:文本坐标系统
这篇文章配有1小时的配套视频,其中Thorsten、Nathan和Antonio首先围绕Points和Offsets编写一些测试,然后深入探讨DisplayPoint和Anchor领域。
在这里观看视频:https://youtu.be/il7NoDUFCWU

Point
首先,让我们谈谈Zed中最明显的文本坐标形式:Point。Point是"文本缓冲区中由行和列组成的从零开始索引的点"。它看起来像这样:
// crates/rope/src/point.rs
struct Point {
row: u32,
column: u32,
}
这里没有什么令人惊讶的。行和列,基本要素。这里有一个我们测试中的片段来说明Point是如何使用的:
let last_selection_start = editor.selections.last::<Point>(cx).range().start;
assert_eq!(last_selection_start, Point::new(2, 0));
这个断言试图确保选择从第3行(从零开始索引!)的第0列开始。
Point的一个便利特性是它们使得沿着行进行导航变得容易。将光标向下移动一行就像增加row值一样简单:
let old_point = Point::new(18, 5);
let new_point = Point::new(point.row + 1, point.column);
从第18行到第19行只需要一个简单的+1。很好。如果你想回去,把它变成-1。但是如果你想向左或向右导航呢?
这可能会变得棘手,因为不同的行可能有不同的长度。简单地增加或减少列数可能会给你一个文档中无效的位置。事实证明,Point的表面简单性有点欺骗性 — Point需要小心处理。
例如,在Zed中,Point遵循Nathan所说的"打字机逻辑":回车 — 本质上是添加一个新行 — 将列计数重置为零,因为在打字机上,滑架也会从下一行的开始处开始。
为了说明这一点,这里有一个在Zed的代码库中通过的测试。请注意列:
fn test_point_basics() {
let point_a = Point::new(5, 8);
let point_b = Point::new(2, 10);
let result = point_a + point_b;
assert_eq!(result, Point::new(7, 10));
}
注意,两行 — 5和2 — 被加在一起,但结果列是10,这是point_b的column值。
用点进行文本数学运算 - 并不像我想象的那么简单。
Offset
偏移量是Zed中的另一种类型和文本坐标系统。它们很直观。Offset是一个绝对数字,表示从文档开始的字符计数作为文档中的位置。
文档的开始是Offset::new(0),Hello World中W的位置是Offset::new(6),文档中的最后一个字符是Offset::new(document.len() - 1)。
当处理跨越多行文本的操作时,偏移量特别有用。例如,选择:
let start = Offset::new(10);
let end = Offset::new(50);
let selection = Selection::new(start, end);
完全不需要担心列 — 从这个字符到那个字符,包括换行符。用Offset表达很容易。
但是,再次,Offset也有一个小陷阱,因为单独的Offset是不够的。
UTF-16,什么?
当探索Zed的代码库时,我发现一个非常有趣的现象,你会发现比Offset更多的OffsetUtf16。还有PointUtf16。我个人从未需要处理UTF-16,除非在处理语言服务器和语言服务器协议时,它使用UTF-16编码来计算和描述文本文档位置和偏移量。
事实证明,这正是Zed拥有OffsetUtf16和PointUtf16的原因:为了与语言服务器通信。例如,这里是一个方法,用于查找缓冲区中给定位置的定义:
fn definition<T: ToPointUtf16>(
&self,
buffer: &Model<Buffer>,
position: T,
cx: &mut ModelContext<Self>,
) -> Task<Result<Vec<LocationLink>>> {
let position = position.to_point_utf16(buffer.read(cx));
self.definition_impl(buffer, position, cx)
}
位置 — 一个实现了ToPointUtf16特质的T — 在被发送到语言服务器之前被转换为PointUtf16。在底层,这可能会调用我们的Rope数据结构上的以下方法:
// crates/rope/src/rope.rs
impl Rope {
fn point_to_point_utf16(&self, point: Point) -> PointUtf16 {
if point >= self.summary().lines {
return self.summary().lines_utf16();
}
let mut cursor = self.chunks.cursor::<(Point, PointUtf16)>();
cursor.seek(&point, Bias::Left, &());
let overshoot = point - cursor.start().0;
cursor.start().1
+ cursor.item().map_or(PointUtf16::zero(), |chunk| {
chunk.point_to_point_utf16(overshoot)
})
}
}
为了理解这里的每一行,我推荐阅读关于Rope和SumTree数据结构的Zed解码文章。现在只需要知道我想要说的是:由于语言服务器的原因,UTF-16对Zed如此重要,以至于用来实现Rope的SumTree已经索引了UTF-16点和偏移量,产生了两个新的文本坐标系统 - PointUtf16和OffsetUtf16 — 并使得与UTF-16的转换非常快速。
DisplayPoints
如果我们爬上抽象梯子,离开偏移量、行和列,我们接下来会遇到DisplayPoint。什么是DisplayPoint?
// crates/editor/src/display_map.rs
struct DisplayPoint(BlockPoint)
DisplayPoint是BlockPoint的新类型。什么是BlockPoint?
// crates/editor/src/display_map/block_map.rs
struct BlockPoint(pub Point);
BlockPoint是一个... Point — 等等,什么?这是否意味着我们根本没有爬上抽象梯子,而是在抽象仓鼠轮中转了一圈?
并非如此!DisplayPoint确实是一个Point,是的,但在这个上下文中 — 在DisplayPoint内部和editor板块内 — Point的行和列有不同的含义。它们不是指磁盘上文本文件中的对应部分,而是指你可以在编辑器内部看到的行和列,即显示的行和列。因此称为DisplayPoint。
看看这个截图:
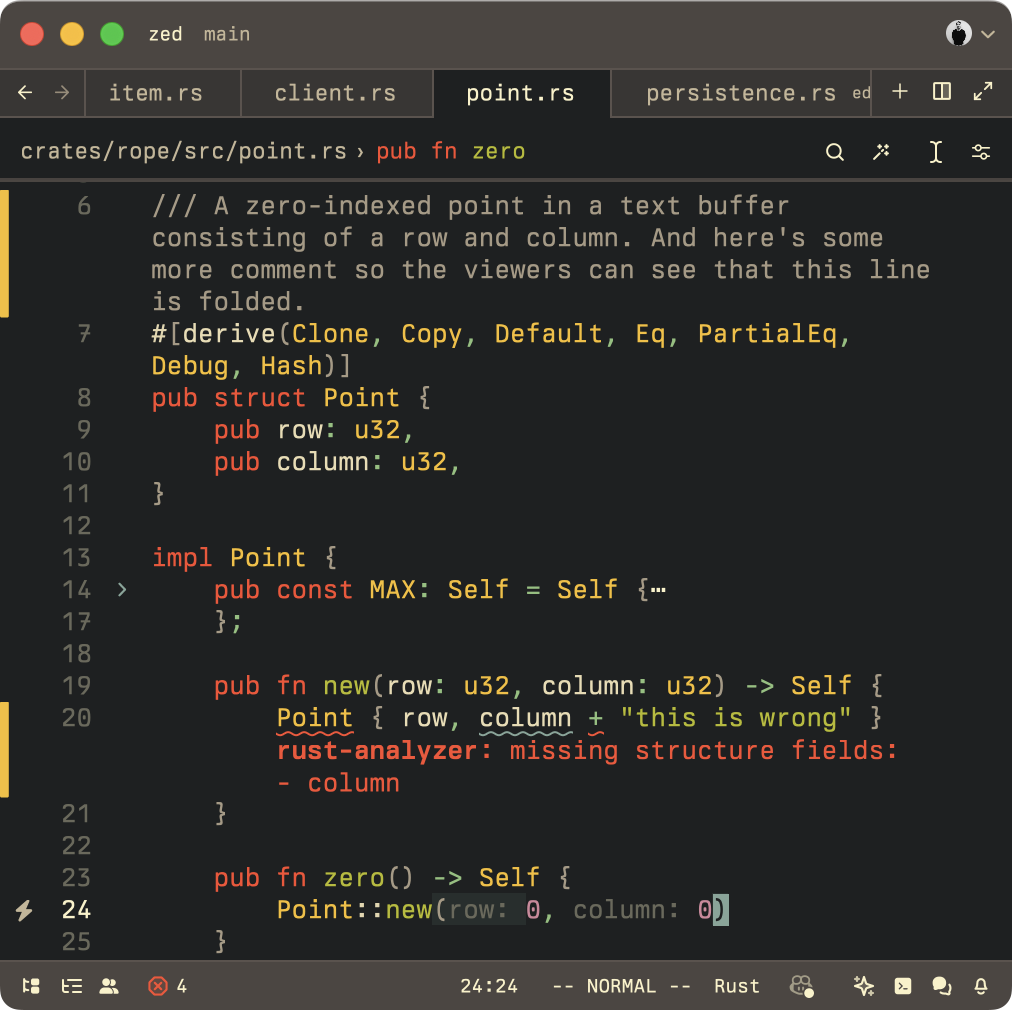
光标在哪里?
光标的位置在哪里?仔细看。作为普通的Point(从零开始索引!),它将是第23行和第23列。但作为DisplayPoint,光标的位置是第29行和第36列!
这是因为DisplayPoint描述的是DisplayMap上的位置(这是我们希望在未来的Zed解码中讨论的内容),并考虑到
- 软换行
- 折叠
- 内联提示
- 制表符
- 块和折痕
在那个截图中,你可以看到第6行是软换行的,占据了多于一行的空间。Point::MAX的定义被折叠了。一个块显示了一个诊断错误。在zero()方法中,光标所在的位置,光标左侧有两个内联提示。
DisplayPoint允许Zed考虑所有这些,并准确描述光标的位置 — 在换行、诊断、折叠、内联提示等之间。
这里是我发现的一个非常能说明DisplayPoint作用的测试的修改版本:
// Modified version of a test in crates/editor/src/display_map.rs
async fn test_zed_decoded(cx: &mut gpui::TestAppContext) {
// [... setup ...]
let font_size = px(12.0);
let wrap_width = Some(px(64.));
let text = "one two three four five\nsix seven eight";
let buffer = MultiBuffer::build_simple(text, cx);
let map = cx.new_model(|cx| {
DisplayMap::new(
buffer.clone(),
font("Helvetica"),
font_size,
wrap_width,
// [... other parameters ...]
)
});
let snapshot = map.update(cx, |map, cx| map.snapshot(cx));
// Given the above constraints — font_size, wrap_width, ... — the text above
// is displayed in 5 lines.
assert_eq!(
snapshot.text_chunks(DisplayRow(0)).collect::<String>(),
"one two \nthree four \nfive\nsix seven \neight"
);
// DisplayPoint(1, 0) is equivalent to Point(0, 8)
assert_eq!(
DisplayPoint::new(DisplayRow(1), 0).to_point(&snapshot),
Point::new(0, 8)
);
// DisplayPoint(1, 2) is equivalent to Point(0, 10)
assert_eq!(
DisplayPoint::new(DisplayRow(1), 2).to_point(&snapshot),
Point::new(0, 10)
);
// DisplayPoint(4, 1) is equivalent to Point(1, 11)
// (This is the "i" in "eight")
assert_eq!(
DisplayPoint::new(DisplayRow(4), 1).to_point(&snapshot),
Point::new(1, 11)
);
}
这个测试说的是什么。给定文本...
one two three four five
six seven eight
... 以及12像素的字体大小,64像素的换行宽度,Helvetica字体,和一堆其他参数,文本将被显示为:
one two
three four
five
six seven
eight
而DisplayMap(这里作为局部变量snapshot中的快照)允许我们在"真实"的Point和DisplayPoint之间进行转换:
Point::new(0, 10)显示在DisplayPoint::new(1, 2)Point::new(1, 11)显示在DisplayPoint::new(4, 1)
很巧妙,对吧?
这里底层有很多东西我很想更深入地研究,但我们已经讲得很长了,所以让我们继续讨论下一个坐标系统。或者至少是我认为会是坐标系统的东西,但事实证明并不是:锚点。
Anchors
在与Nathan和Antonio的对话之前(你可以在这里观看配套视频),我知道锚点的存在 — 我在代码库中看到过Anchor类型和各种相关方法 — 并假设它们是另一种表示文本文档中位置的方式 — 另一个坐标系统。
事实证明,这个假设有点错误。锚点确实与文本文档中的位置有关,但与Points、Offsets或DisplayPoint非常不同。
假设你有这样一个文本文档:
Hello World!
一个Anchor允许你指向这个文档中给定字符的一侧 — 左侧或右侧。例如,你可以创建一个指向这里W左侧的锚点。这接近于Point::new(0, 6),但并不完全相同:Point描述的是W在这个版本文档中的位置,而Anchor会粘附在W的侧面,即使在编辑后也是如此。
用Nathan的话说:
锚点是一个逻辑坐标。你可以在一个字符的右侧或左侧创建一个锚点。然后,在未来的任何时候,你总是可以兑现这个锚点,获得你本质上标记或锚定的字符的位置。即使在此期间发生了编辑,即使那段代码被删除了,或者那个字符被删除了,你仍然可以获得它的墓碑位置 — 如果它没有被删除的话它会在的位置,或者如果那个删除被撤销它会出现的位置。
所以如果我们在上面的W的左侧附加一个锚点,然后文本文档被编辑成这样:
Hello and good day to you, World!
我们仍然可以取我们的锚点并"兑现"它,将其转换为W现在所在的实际Point。
这对于协作文本编辑器来说完全有意义:如果你的光标位于W上,有人来编辑它左侧的文本,你希望你的光标保持在W上,而不是让文本地板在你的光标脚下改变。
如果你看看Anchor的定义,你可以看到它与Zed的协作性质和CRDT有多么密切的联系:
// crates/text/src/anchor.rs,稍微简化
/// 缓冲区中的带时间戳的位置
struct Anchor {
timestamp: clock::Lamport,
/// 缓冲区中的字节偏移量
offset: usize,
/// 描述锚点偏向哪个字符
bias: Bias,
buffer_id: Option<BufferId>,
}
这里的timestamp是一个Lamport时间戳,一个逻辑时间戳。在我们的对话中,Antonio说这里的timestamp不是一个好名字,它过去被称为id,这也是一个更好的思考方式。Nathan解释道:
在CRDT中,或至少在我们的CRDT实现中,每一段文本,无论是一个字符还是一大块粘贴的文本或其他插入的东西,都被视为一个不可变的块。这个不可变的块被赋予一个唯一的ID,一个在整个集群中唯一的ID。
上面的timestamp: clock::Lamport就是这个ID。Nathan继续说:
[...] 基本上,这是一种获得唯一ID的方式,对吧?唯一性是从副本ID继承的,然后每个副本当然可以通过增加它们的序列号来全天候生成新的Lamport时间戳。它实际上是一个插入的ID,是原始插入文本块的ID。
所以,timestamp是分配给不可变文本块的唯一ID。然后offset描述了Anchor在这段不会改变的文本中的位置,因为,再次强调,它是不可变的。Nathan谈到不可变性:
一旦我们插入它,它就是不可变的。如果你删除其中的部分,我们可能会隐藏它们,给它们做墓碑标记,但它们仍然在那里。这就是我们实现协作的方式。整个事情是单调递增的。它只是随着时间的推移积累数据。正因为如此,我能够引用插入ID,无论什么,偏移量,无论什么。现在有很多索引和花哨的东西来确定它现在究竟在哪里。但至少这是我们可以引用的稳定的东西。这就是我们选择锚定它的原因。
用Nathan的话说,Anchor是"这个单调增长结构的一个锚点"。
但这里最妙的部分是:这不仅对协作有用!锚点也用于文本的后台处理。想想看:你想把一段文本发送给,比如说,在后台运行的语言服务器。你创建两个锚点 — 选择的开始和结束 — 并用这两个锚点启动一个后台进程,将文本发送给语言服务器。同时,用户可以继续输入和更改文本,因为这两个锚点将永远有效,因为它们锚定在一个不可变文本块的位置上。
就是这样 — Point、Offset、UTF-16对应物、DisplayPoint、Anchor — 谁能想到我们会从行和列走到Lamport时钟?